



LLMs are getting cheaper. OpenAI just released GPT-4o mini, a highly cost-efficient small model designed to expand AI applications by making intelligence more affordable.
Priced at 15 cents per million input tokens and 60 cents per million output tokens, GPT-4o mini is 30x cheaper than GPT-40 and 60% cheaper than GPT-3.5 Turbo.
OpenAI chief Sam Altman made a cost comparison, saying, “Way back in 2022, the best model in the world was text-davinci-003. It was much, much worse than this new model. It cost 100x more.”
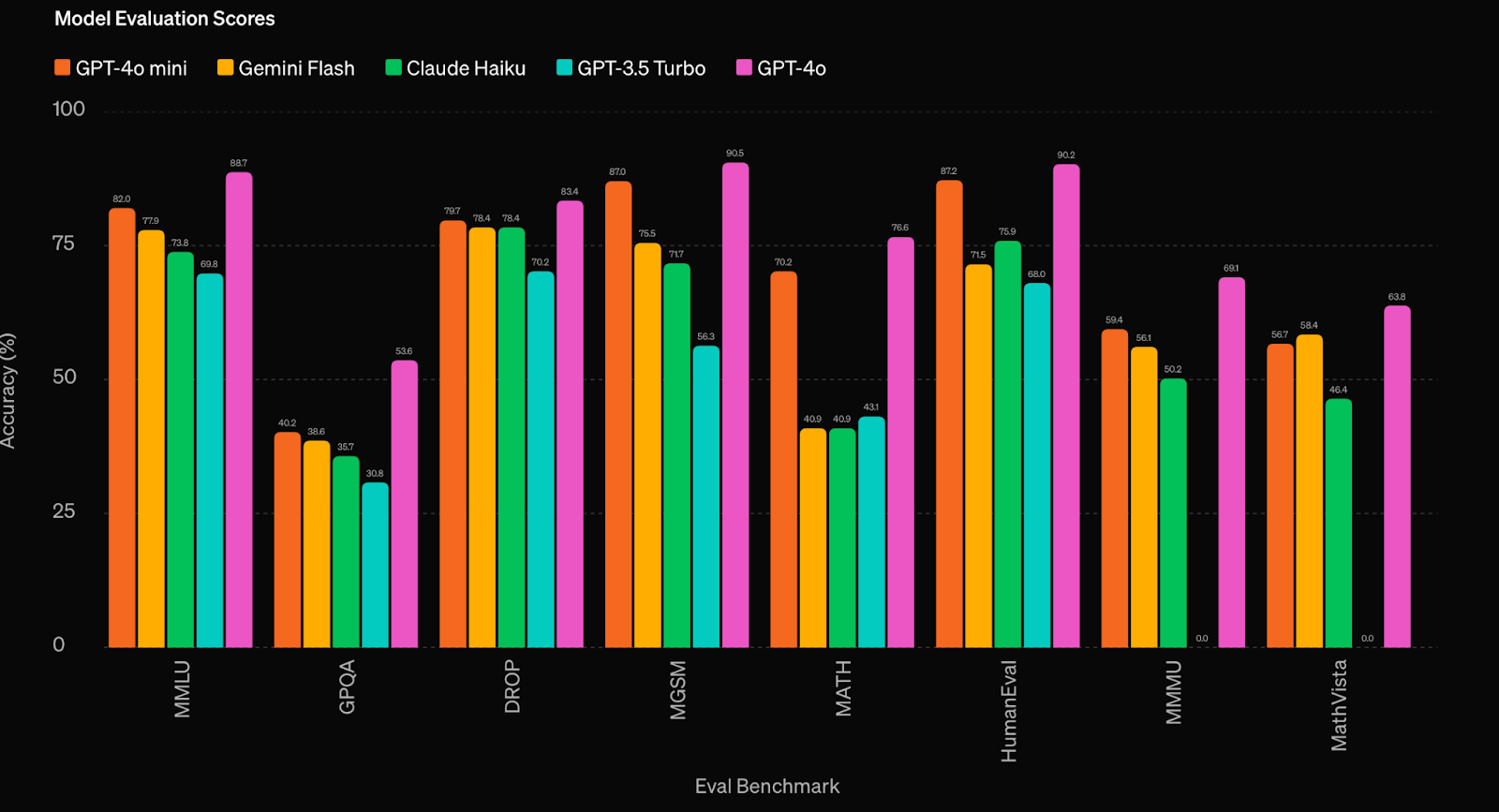
The model excels in various tasks, including text and vision, and supports a context window of 128K tokens with up to 16K output tokens per request. GPT-4o mini demonstrates superior performance on benchmarks, scoring 82% on the MMLU, 87% on MGSM for math reasoning, and 87.2% on HumanEval for coding tasks. It outperforms other small models like Gemini Flash and Claude Haiku in reasoning, math, and coding proficiency.
GPT-4o mini’s low cost and latency enable a wide range of applications, from customer support chatbots to API integrations. It currently supports text and vision, with future updates planned for text, image, video, and audio inputs and outputs.
Safety measures are integral to GPT-4o mini, incorporating techniques like reinforcement learning with human feedback (RLHF) and the instruction hierarchy method to improve model reliability and safety.
GPT-4o mini is now available in the Assistants API, Chat Completions API, and Batch API. It will be accessible to Free, Plus, and Team users in ChatGPT today, and to Enterprise users next week. Fine-tuning capabilities will be introduced soon.
GPT-4o mini comes after OpenAI co-founder Andrej Karpathy recently demonstrated how the cost of training large language models (LIMs) has significantly decreased over the past five years, making it feasible to train models like GPT-2 for approximately $672 on “one 8XH100 GPU node in 24 hours”.
“Incredibly, the costs have come down dramatically over the past five years due to improvements in compute hardware (H100 GPUs), software (CUDA, cuBLAS, cuDNN, FlashAttention) and data quality (e.g., the FineWeb-Edu dataset),” said Karpathy.
That explains how Tech Mahindra was able to build Project Indus for well under $5 million, which again, is built on GPT-2 architecture, starting from the tokeniser to the decoder.
It would be interesting to see what innovative applications developers will create using this new AI model.
Looks like it’s already in motion. A few days back a mysterious model had appeared on the Chatbot Arena. Unsurprisingly, that model is none other than GPT-4o mini.
With over 6K user votes, the model reached GPT-4 Turbo performance.
























